Bis zur Beendigung meiner beruflichen Laufbahn habe ich mit allen Versionen von SAP BW bis einschl. 7.5 gearbeitet. In der Anfangszeit hat es für die Architektur eines DWH auf Basis SAP BW keine Architekturvorgaben gegeben. Entsprechend sahen die Anwendungen aus. Dazu kam, dass die Leistungsfähigkeit der Hardware aus heutiger Sicht recht bescheiden war. Wenn ich das noch richtig in Erinnerung habe, waren bei den ersten Versionen von SAP BW durchaus Transformationen an den Daten bereits im Quellsystem üblich. Da gab es Exits und ABAP-Erweiterungen im Quellsystem. Die Daten wurden +/- mundgerecht während der Extraktion aufbereitet und dann tröpfchenweise in das BW-System übertragen.
Status: In Überarbeitung.
Referenzarchitekturen
Ich bin momentan noch auf der Suche danach, wann SAP das erste Mal eine Referenzarchitektur veröffentlichte. Muss so um Version 3.2 gewesen sein, bin mir da aber nicht sicher. Dieses war die Layered Scalable Architecture. Das Staging der Daten wurde verschlankt, Transformationen fanden nur noch im BW-System selbst statt, sofern nicht kundeneigene Erweiterungen in der Extraktion notwendig waren. Damit verschlankte sich das ETL, aus Sicht eines Supporters, erheblich. Fehlerquellen lassen sich so wesentlich besser lokalisieren, der Ladevorgang wurde stabiler.
Die Anforderungen an eine Referenzarchitektur ergeben sich aus den Anforderungen an ein BW-System:
- Datenqualität und -konsitenz
- Vermeidung von Redundanzen / Inseln
- Wiederverwendbarkeit von Objekten und Daten. Dieses betrifft vor allem auch Stammdaten
- Wartungsfähigkeit der Anwendung
- Single Point of Truth (Spot)
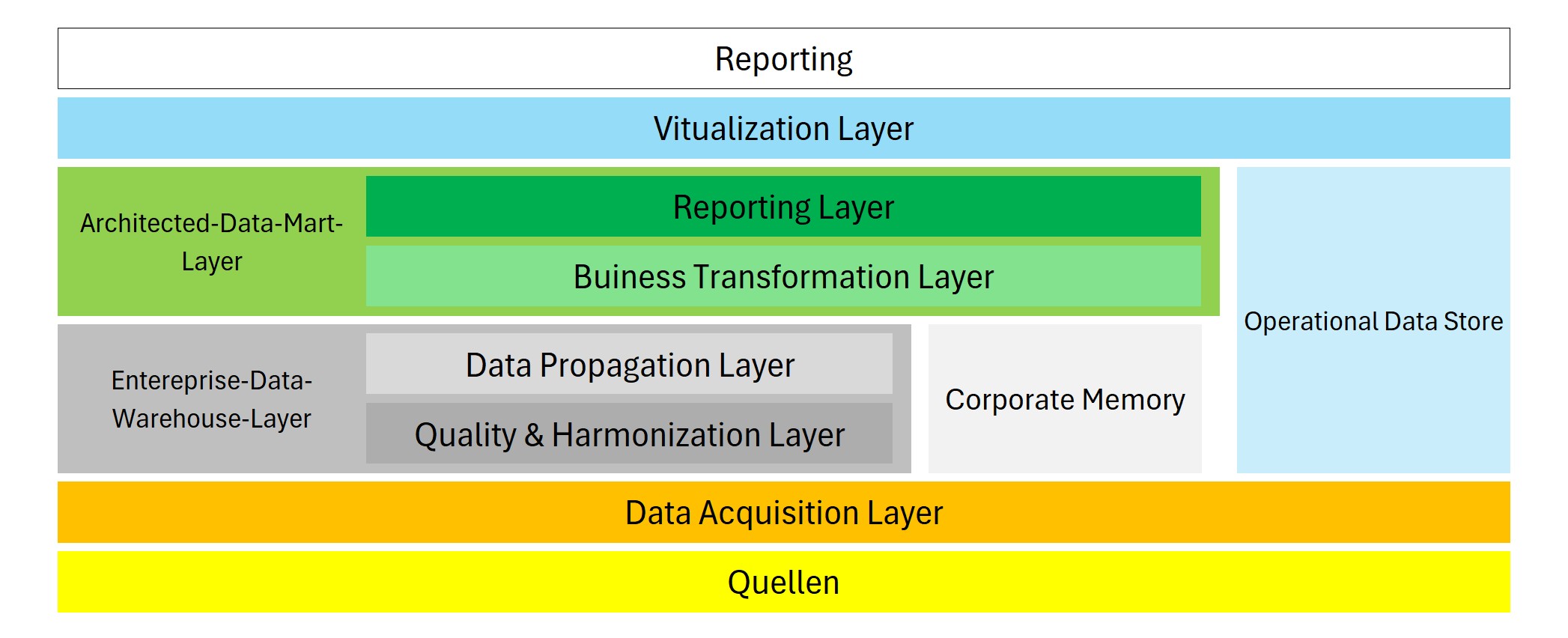
Die LSA beschreibt den konzeptionellen Aufbau eines EDW, regelt das Staging in der Anwendung.
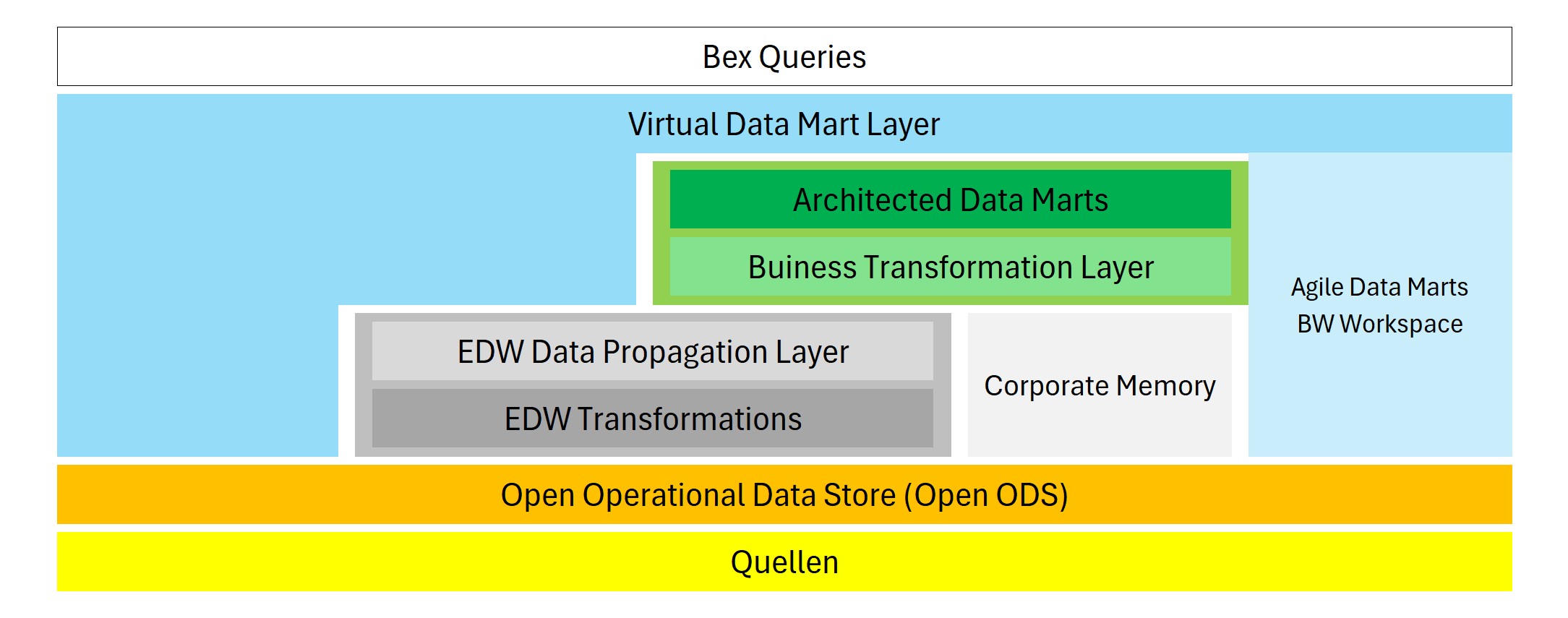
Mit der Einführung von SAP HANA wurde die Referenzarchitektur entsprechend angepasst.
Layer
Layer können, müssen aber nicht vorhanden sein. Das Vorhandensein eines Elementes richtet sich nach den Anforderungen an das Reporting.
Datenbeschaffung
- LSA: Data Acquisition Layer
- LSA++: Open Operationan Data Store
Data Aquisition Layer
- PUT
- Persistent
- Anbindung der Quellsysteme
- Dateneingang in die Anwendung, Übernahme der Daten aus der Extraktion im Quellsystem
- Persistance Staging Area (PSA), bis zur Version 3.4? musste über die PSA verbucht werden, danach konnte die PSA genutzt werden
- Die PSA kann als Kurzzeitspeicher für die Beladung verwendet werden, falls eine Beladung wiederholt werden muss
- Übertragene Daten können alternativ zur PSA in schreiboptimierten DSO aufgenommen werden
Open Operational Data Store
- GET
- SAP HANA hat einen neuen Zugriffsmodus auf die Daten in Fremdsystemen
- Operational Data Queue (ODQ), PSA wird dadurch obsolet, Daten können direkt, ohne Transformation, in ein aDSO geladen oder repliziert werden. Keine Zuordnung auf InfoObjekts notwendig, das aDSO wird i. R. auf Basis der DataSource-Felder definiert
- Das Open ODS kann direkt in das Reporting eingebunden werden, schnelle und agile Bereitstellung von Informationen
- Dies wird erreicht durch:
- Definition von wiederverwendbaren BW Semantiken auf den feldbasierten DataStore-Objekten (advanced) der Open-ODS-Schicht mit Hilfe von virtuellen Open ODS Views:
- Rolle des DataStore-Objekts (advanced) (Fakten, Stammdaten, Texte)
- Bedeutung der Felder (Merkmal, Kennzahl, Währung,…)
- Definition von Assoziationen zwischen Open ODS Views (Fakten und Dimensionen: Star Schema, Stammdaten und Texte)
- Definition von Assoziationen zwischen Open ODS Views und InfoObjects (s.u.)
- Kombination von Open ODS Views mit anderen InfoProvidern der Propagation- oder Architected-DataMart-Schicht über CompositeProvider
- Unmittelbares Querying auf der Open-ODS-Schicht über Open ODS Views und CompositeProvider
- Definition von wiederverwendbaren BW Semantiken auf den feldbasierten DataStore-Objekten (advanced) der Open-ODS-Schicht mit Hilfe von virtuellen Open ODS Views:
Enterprise Data Warehouse Layer
- Herstellung des SPOT (Single Point of Truth)
- Zusammenführung von Daten aus unterschiedlichen Quellsystemen
- Harmonisierug der Daten
- Fehlerbereinigung
- EDW – Layer besteht aus einem Aktionslayer und einem persitenten Layer
- LSA: Quality & Harmonization Layer
- LSA++: EDW Transformations
Architected Data Mart Layer
- Bereitstellung der Daten für die Anforderungen des Reportings
- Besteht aus einer Aktionsebene und einem Persistenten Layer
- Business Transformations
- LSA: Reporting Layer
- LSA++: Architected Data Marts
Corporate Memory
- In der Corporate Memory befindet sich die Historie der gespeicherten Daten
- Quelle für Rekonstruktionen ohne erneuten zugriff auf Quellsysteme
- Auf konventionellen DB basierenden BW kann diese Funktion von der PSA oder von DSO übernommen werden
- Auf HANA basierten Systemen geschieht die Speicherung in aDSO
- Das Corporate Memory wird unabhängig von der Fortschreibung in die Architected-Data-Marts gefüllt.
- Die Speicherung der Daten erfolgt im CM mit dem entsprechenden Modellprofil.
- Das Staging der Daten muss entsprechend den Anforderungen unabhängig vom üblichen Datenfluss eingerichtet werden
AdHoc Bereich
Data Warehousing ist eine strukturierte Auswertung von Daten, ein Warehouse enthält entsprechend Daten für bekannte Auswertungen bereit. Kurzfristig auftretende Fragestellungen können unabhängig hiervon im AdHoc – Bereich aufgegriffen werden.
- LSA: Operational Data Store
- LSA++: Agile Data Marts / BW Workspace
Datenbereitstellung
- Zusammenfassung mehrerer persistenter Datenquellen für ein Reporting
- Kapselung über JOIN und MERGE
Unterschiede
Unterschiede in den Architekturen sind zunächst technisch bedingt durch einen unterschiedlichen Aufbau der zugrunde liegenden Datenbank. Damit können viele Konstrukte im Bereich der persistenten Elemente entfallen. Neben der Vereinfachung sind die neuen Elemente (aDSO) universeller, können flexibler eingesetzt werden.
Es gibt Unterschiede in der Art, wie BW-Systeme ihre Daten beschaffen.
LSA++ wesentlich näher an SQL als LSA, viertuelle und persistente Elemente entsprechen gekapselten Elementen SQL
Änderungen
LSA++ ist eine Anpassung der Architektur der LSA auf die Umgebung innerhalb einer SAP HANA-Datenbank
Spaltenorientierte Datenbank
Die Spaltenorientierung der Datenbank mach das Sternschema der BW-Systeme aus der klassischen Welt obsolet.
Vereinheitlichte und universellere Elemente
Virtuelle Elemente
Der Composit Provider fasst die Elemente
Persistente Elemente
aDSO ersetzt InfoCube, PSA

Nähe zur Datenbank
Datenflüsse innerhalb SAP BS4/HANA lassen sich als Mischung aus DBMS SQL und BW-Objekten realisieren. Man verliert dann aber Vorteile des ABAP-Layers der Kapselung von Eigenschaften (Datenkonsistenz)
Näher am DBMS als bei BW-Systemen auf Basis konventioneller Datenbanken