Aufbau eines Data Warehouses
Modell Lager

Ich fange einmal mit einem einfachen Modell eines Warenlagers an, oder zumindest mit dem, was ich als Laie in Sachen Logistik dafür halte. Da sind zunächst zwei Enden, der Wareneingang und der Warenausgang.
Im Wareneingang werden die Güter entgegengenommen, die zuvor bestellt worden sind. Wie dieser Bestellvorgang abläuft, kann durchaus für Beschaffungsvorgang relevant sein. Die Waren können einzeln bestellt werden. Der Lieferer stellt dann die Lieferung zusammen und versendet sie über einen Spediteur zu meinem Lager, wo die Güter angenommen werden und die Lieferung überprüft wird und die Teile in das Lager verbracht werden. Möglich ist aber auch, dass die Daten über einen globalen Vertrag zur Verfügung gestellt werden. Ich schicke dann jemanden in das Lager des Lieferers und lasse das gewünschte Material abhohlen. Der Weg ist durchaus nicht unüblich, wie ich bei meiner KFZ-Werkstatt durchaus erlebt hatte. Teile für die Reparatur waren nicht auf Lager, die Ersatzteile wurden dann aus dem Lager des Herstellers bedarfsgerecht abgehohlt.
Auf der anderen Seite, der Warenausgang. Hier werden die Daten entsprechend den Anforderungen bereitgestellt.
Sternmodell und erweitertes Sternmodell
s. Sternschema
Einfaches Modell eines Data Warehouses
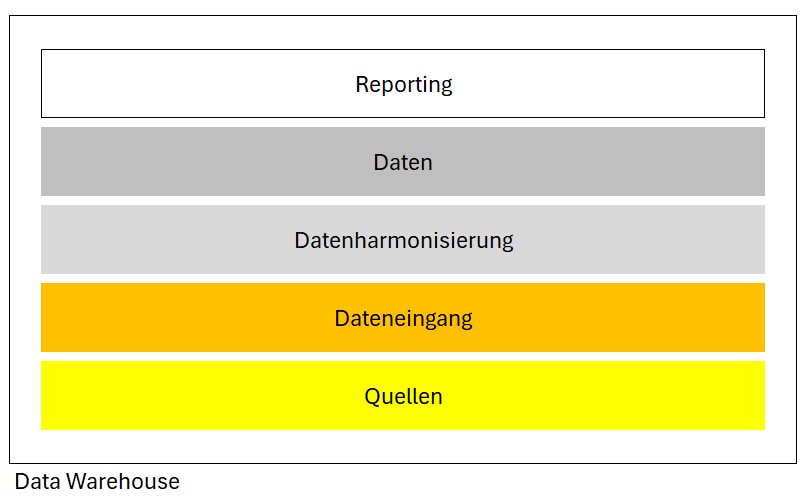
Ich will einmal mit einem einfachen Data Warehouse beginnen, folge dabei meinem Lagermodell.
Ein Data Warehouse ist eine Datenbank, die als OLTP konzipiert ist. Der Aufbau ist unabhängig von der verwendeten Datenbank und kann auch mit SQL implementiert werden.
SAP Referenzarchitektur
ABAP Dictionary
Die Welt der SAP umfasst sowohl die transaktionale Welt als auch die des OLTP. Dadurch werden einige Probleme, grade in Richtung Konsistenz vermieden. Kernelement der SAP ist die Programmierung in ABAP. Basiswerkzeug für die Definition von Feldern ist das DDIC, das Data Dictionary oder auch ABAP Dictionary. Eigentlich ist es umgekehrt, aber an dieser Stelle einmal Scheiß drauf: Das DDIC ähnelt in Funktion den InfoElementen im SAP BW. Es kapselt sowohl die Form der Eingabe, Speicherung, Darstellung und Aggregation als auch die sprachabhängigen Texten. SAP-Systeme sind deswegen (weitestgehend) unabhängig von den Herstellern der Datenbank, auf der das SAP System aufgesetzt worden ist. Das vermeidet viele Probleme beim ETL-Prozess (Datenkonsistenz)
Es gibt in der Welt der SAP Data Warehousing zwei Welten, die ältere, basierend auf der Architektur eines konventionellen Datenbankmanagementsystems und eine Neue auf Basis von SAP HANA. Die Welt von SAP HANA bringt von ihrer Struktur bereits viele Features mit, welche viele Strukturen aus der konventionellen Welt überflüssig machen.
SAP Layered Scalable Architecture (LSA)
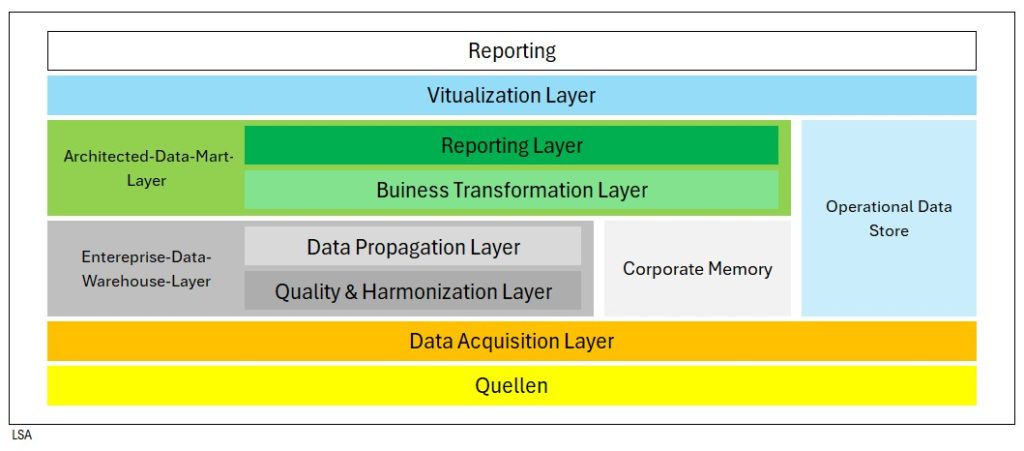
Konventionelles DBMS
SAP Layered Scalable Architecture++ (LSA++)
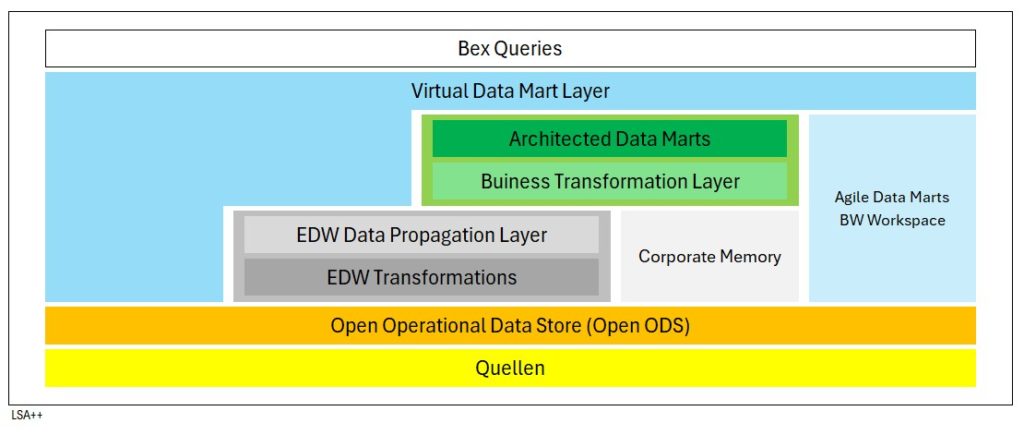
SAP HANA DBMS
Der Übergang zwischen den Welten ist nicht abrupt vollzogen worden, über Zwischenversionen (7.x) sind die Features sukzessive Eingeführt worden.
Beide Architekturen sind strukturell identisch. Die Unterschiede resultieren aus den universelleren Datenflusselementen und Fähigkeiten der SAP HANA Datenbank.
Architekturwelten
Sind bestimmt durch die Fähigkeiten und Struktur der Datenbank und den daraus resultierenden Modellierungselementen.
SAP Layered Scalable Architecture (LSA)
Konventionelles DBMS
Elemente:
- InfoObject
- HybridProvider
- InfoCube
- DataStore Objekct
- PSA
- CompositProvider
- MultiProvider
- InfoSet
- VirtualProvider
Datenzugriff:
- PUT
SAP Layered Scalable Architecture ++ (LSA++)
SAP HANA DBMS
Elemente:
- InfoObject
- Advanced DataStore Object
- Open ODS View
- CompositProvider
Datenzugriff Quellsysteme:
- GET
Layer
Layer können, müssen aber nicht verwendet werden.
Dateneingang
SAP BW/4HANA unterscheidet sich grundlegend gegenüber SAP BW auf Basis konventioneller DBMS beim Zugriff auf die Daten der Quellsysteme.
Corporate Memory
Bereich, in dem eine Kopie der eingegangenen Daten abgelegt wird um eine Historie der Daten zu bekommen. Das Corporate Memory dient dazu, den Datenbestand ohne Zugriff auf die Quellsysteme wieder Aufbauen zu können.
Die Datentemperatur der Daten im Corporate Memory ist kalt, so dass HANA die Daten aus dem Arbeitspeicher auf das Datenarray auslagern kann.
Enterprise-Data-Warehouse-Layer
Ebene auf der die eingeganenen Daten aus den Quellsystemen bereinigt und harmonisiert werden.
Fuktional ist die Ebene in beiden Welten gleich.
Architected-Data-Marts-Layer
Ebene der für das Reporting bereitgestellten Daten entsprechend den Vorgaben des Business. Funktional ist die Ebene in beiden Welten gleich, unterscheidet sich jedoch durch die Fähigkeiten der verwendieten Modellierungselemente
- LSA: Reporting Layer
- LSA++: Architected Data Marts
In beiden Welten werden die Daten über die Business Transformations aus den persistenten Ebenen des Enterprise-Data-Warehouse-Layer aufbereitet.
Modellierung:
- LSA: InfoCube, MultiProvider, CompositProvider
- LSA++: CompositProvider, aDSO